Non-ascii characters displayed as code points in files
NOTE: As of writing the version of Emacs I used is GNU Emacs 27.2 (build 1, x86_64-w64-mingw32) of 2021-03-26.
Sometimes when opening files in Emacs you may see them containing non-ascii characters displayed as code points. It’s because the file is displayed in the wrong encoding. This happens because files don’t really have an accurate description of what encoding they should be displayed with in themselves (see this discussion). So Emacs has to do some guesswork according to the current language environment. If the encoding with which the file should be displayed is not supported by the current language environment, it would be displayed in a wrong encoding so the characters would look messed up. For example, when you open a file originally encoded in Chinese-GBK in the English language environment it would display code points in place of Chinese characters because the English language environment doesn’t have an encoding scheme that supports Chinese characters.
To see your current language environment check the variable current-language-environment. To see what coding systems are supported by a language environment use the command describe-language-environment (C-h L). To check the current encoding of the character at point use what-cursor-position (C-u C-x =). The leftmost character on the mode line indicates the current buffer’s encoding. For example, U indicates the UTF-8 encoding. You can hover mouse on it to show the tooltip. The area right next to the encoding area tells the EOL (End of Line) style used for the current buffer, such as Unix (LF), Windows (CRLF), or Mac (CR).

To change the current buffer’s encoding you can right click the encoding area on the mode line, or call set-buffer-file-coding-system, and then choose a desired coding system. Emacs coding systems can specify both character encoding and EOL style. For example, utf-8-unix means using UTF-8 and UNIX EOL. You can see details about a coding system with describe-coding-system. You can also see the current buffer’s encoding by checking the variable buffer-file-coding-system.
To fix this problem, you can use a compatible language environment. If you know what language the characters are supposed to be, or better what encoding they should be displayed with, you can narrow down the choices under Options > Multilingual Environment > Set Language Environment, which sets the value of the variable current-language-environment to the selected one. You can also use the command set-language-environment (C-x RET l). For example, if a file is originally encoded in Chinese-GBK, to display it correctly, change the language environment to Chinese-GBK (C-x RET l Chinese-GBK), then kill the file without saving and open it again.
You may use decode-coding-string and encode-coding-string to find out the correct encoding of the characters. For example,
(decode-coding-string "\304\343\272\303\243\254\312\300\275\347" 'gbk)
(encode-coding-string "你好,世界" 'gbk)
You can also display the characters correctly without changing the language environment, that is, using the command universal-coding-system-argument (C-x RET c) before opening the file, e.g. C-x RET c chinse-gbk C-x C-f <your-file>. Or if the file is already open, you can run the command revert-buffer-with-coding-system (C-x RET r) to revert the buffer in the desired encoding, e.g., C-x RET r chinese-gbk.
When the file is displayed correctly you can save it in another encoding. Use either universal-coding-system-argument (C-x RET c) or set-buffer-file-coding-system (C-x RET f) before saving it. Some examples:
C-x RET c utf-8 RET C-x C-w <new file name> RET
C-x RET f utf-8 RET C-x C-w <new file name> RET
These commands are also listed under Options > Multilingual Environment > Set Coding Systems.
Some other utility buffers may also display non-ascii characters incorrectcly. You can follow a similar approach as described above to resolve these kinds of problems. For example, Eshell buffers may not display or read Chinese characters as expected if your current-language-environment is English and your native shell’s encoding is Chinese-GB:
The Eshell buffer couldn’t display the output of the tree command correctly:
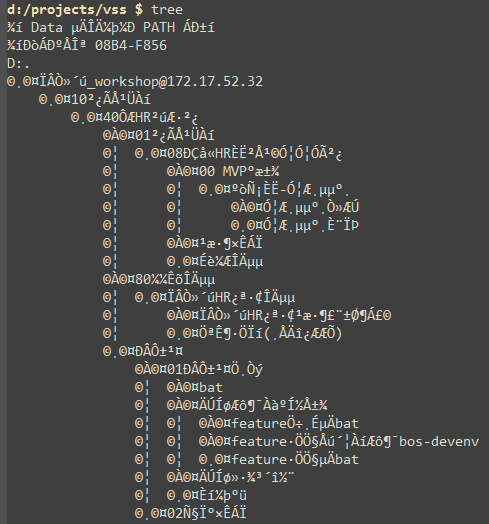
The Eshell buffer couldn’t find the file with Chinese characters in its name using es:


Comments